小编最近在折腾一个桌面全文搜索引擎。本来以为流程很简单:
文件 → 分词 → 建索引 → 搜索
结果第一步就被现实教育了。作为典型小松鼠属性的小编,电脑里囤了一堆 PDF:论文、扫描书、资料、电子书……
看起来都是文字。但实际上很多都是——影印版。本质就是:一张张图片。
这些 PDF 如果不先 OCR 成文字:
-
Ctrl+F 搜不到
-
无法建立索引
-
知识库直接废掉
也就是说:OCR 其实是全文搜索的第一道门槛。
我试了几个 OCR 方案,说实话有点崩溃 😅
为了给全文搜索做数据,我试过:
1️⃣ 自己写 Python 代码
最开始的想法很简单:用 Python + OCR 库,自己搞一套。结果很快发现问题:
不同 PDF 的情况完全不一样:
-
扫描件
-
双栏论文
-
表格
-
乱码编码
-
图片+文字混排
每种情况都要写不同逻辑。工程量直接指数级增长。最后结论只有一句:
人还是要对自己有点清醒认知。
2️⃣ Adobe Acrobat Pro
功能确实强。但问题也很明显:
-
启动慢
-
资源占用高
-
功能多到有点复杂
新手小白不想上手。
3️⃣ ABBYY FineReader
老牌 OCR 软件。识别效果不错。但问题也有两个:
-
价格不太友好
-
有些版本 离线 OCR 不太理想
对于经常处理 PDF 的人来说,成本其实不低。
几欲崩溃的边缘,我发现了 MinerU 👀
MinerU,它的思路和传统 OCR 不太一样。简单理解就是:
PDF → 结构化内容
而不只是识别文字。
比较让我惊喜的几个点:
✔ 支持 109 种语言
中英混排、论文、技术文档都能处理
✔ 输出 Markdown / JSON
对开发者非常友好
✔ 保留文档结构
标题、列表、段落顺序基本都能还原
✔ 自动去页眉页脚页码
这个细节真的很关键
另外一个比较舒服的点是:服务器解析,速度比很多本地 OCR 快。
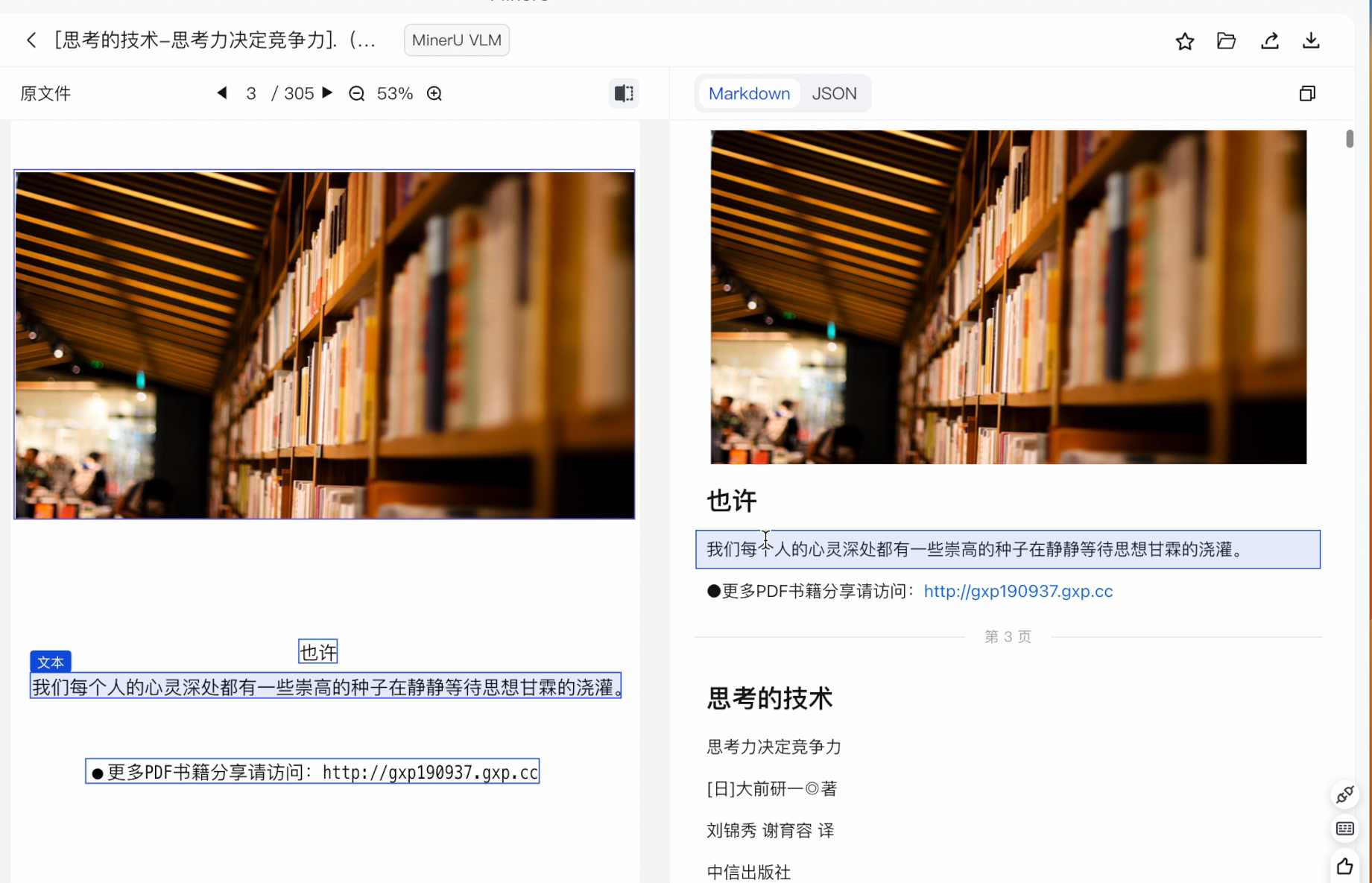
软件界面还能看到:原文 + 解析结果对照。而且导出的文件除了 Markdown,还有 JSON 结构。
里面甚至记录了:
-
文字框位置
-
文本内容
-
页面结构

对做:知识库、RAG、全文搜索 的人来说,确实挺有吸引力。
OCR 到底有没有“最优解”?
用了一圈工具之后,我反而有点疑问:OCR 到底有没有“最优解”?
不同人的需求其实完全不同:
有人只想
👉 复制文字
有人想
👉 做知识库
有人想
👉 训练 AI
工具评价一下就不一样了。
比如最近很火的:
-
PaddleOCR
-
Tesseract
-
MinerU
-
PDF-Extract-Kit
其实各有优劣。你们平时怎么处理 PDF?有哪款工具?评论区分享出来。有时候一个工具推荐,可能能救别人一整天的时间 😂
下载地址
